Background
Like a lot of people, I have a small number of sites I check regularly for new content. These include things like Reddit, Hacker News, ESPN, and my YouTube subscriptions. That said, I obviously don't monitor these sites constantly, nor am I interested in everything that appears on them.
Given I both value my time and check these sites often, this seemed like a great opportunity for automation. My primary goal would be to build a system that could exercise the same judgement I would if I were to watch these sites constantly, a system that would only alert me about new and interesting content.
More broadly, I wanted to build a personal dashboard that could serve as the central hub of my web browsing, of which checking these sites was a regular component.
My Solution
My solution to the problem is the lil ai Personal Dashboard, a Chrome extension based new tab page dashboard that performs real-time website content and subscription monitoring and prioritization. It also provides enhanced search capabilities as well as other helpful features such as a clean, minimalist design, a weather shortcut, a calendar, and web viewing statistics.
That's obviously a lot to absorb at once, so let's take that piece by piece:
Chrome Extension
The Personal Dashboard is an add-on to the lil ai Chrome extension platform I discuss in other posts (Voice Assistant & Search Assistant). I discuss the benefits of Chrome extensions more generally in some of these other posts, but for this specific project its major benefits are its excellent scraping ability and the ability to allow a custom new tab page.
New Tab Page
Custom new tab pages are some of the most popular and useful extensions found in the Chrome Web Store. This is because they're an ideal launching point and central hub for web browsing activity, great for starting searches, suggesting favorites, etc. Similarly, they're also great for reminders or alerts since they'll be seen often: every time a new tab or window is opened.
Ultimately, given these benefits, a custom new page combined with setting that page as my home page is the ideal location for my Personal Dashboard.
Real-Time
Perhaps the most significant technical achievement of my Personal Dashboard is that everything happens in real-time. In ~2 seconds (see demo video below for evidence) it accomplishes all the following actions:
- Renders the page
- Gathers data from 4 different sites (Reddit, YouTube, ESPN, and Hacker News)
- Flags new content and ignores previously seen content
- Runs the new content data through a recommendation / prioritization model (currently for Reddit only)
- Displays the results
Similarly all of the enhanced search features all happen in real-time as well. This includes:
- Fetching recommended (autocomplete) search queries
- Performing a Google search on the query
- Performing a search of my past browsing history on the query
- Fetching the top answer from Stack Overflow (where applicable)
- Displaying the results
Content / Subscription Monitoring
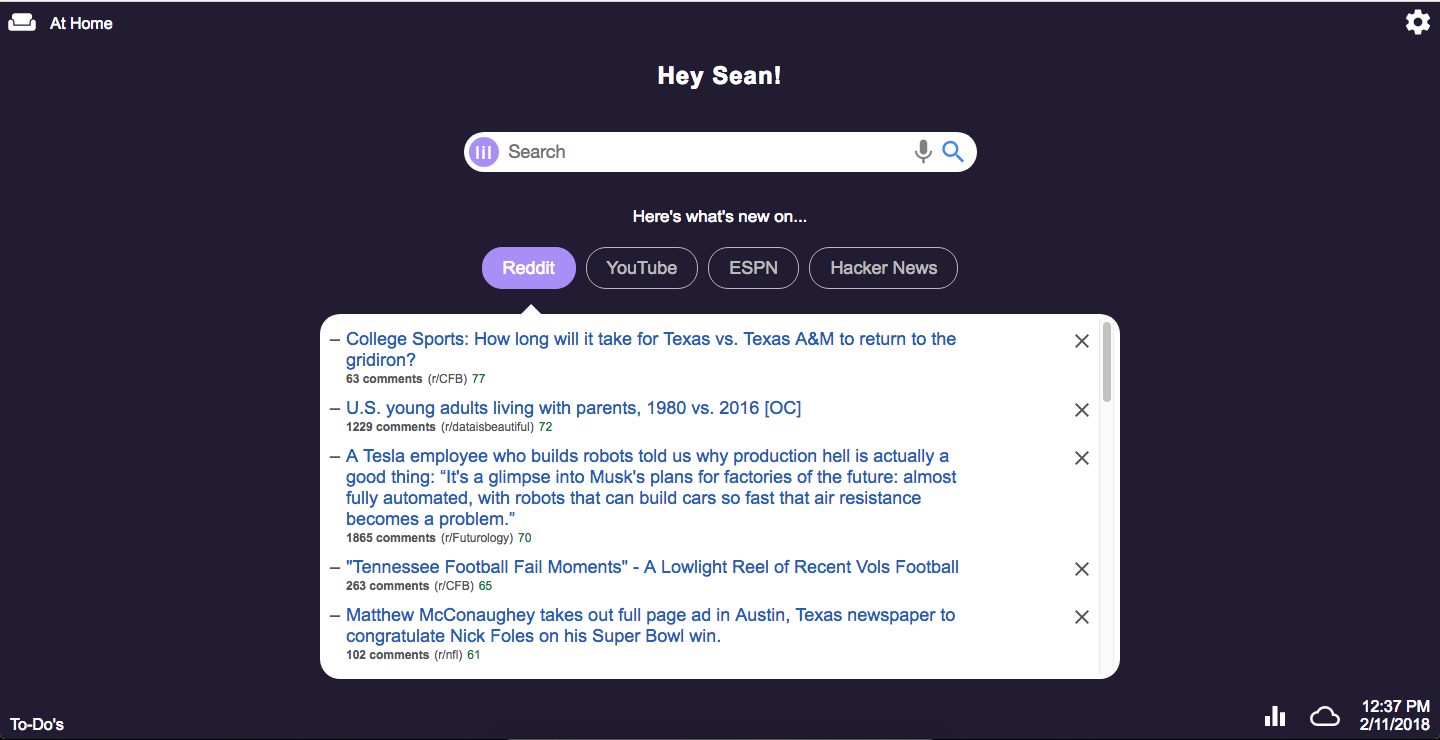
As mentioned, my Personal Dashboard currently monitors 4 different sites. These are specifically:
- Reddit (my front page with manually curated subreddits)
- YouTube (my subscriptions)
- ESPN (top headlines and college football headlines)
- Hacker News (front page)
Each requires custom data acquisition tailored to that source's idiosyncrasies. Reddit has an API (thank you Reddit!). All others are scraped (thank you Chrome extensions!).
Basic parsing of the API results / html happens in Javascript, and the cleaned data is sent to a locally hosted Python server. The Python server tracks and persists the raw data in addition to data on what content has been seen / is new, has been viewed / watched or not, etc. By comparing against its database of previously seen content, the server returns only the new content items for display.
Finally, the results are displayed on the front end (as seen for Reddit in the picture above). I can either click on, dismiss (X out), or ignore each content item. Whenever I take an action, the new status of that item is sent back to the Python server for future reference. Dismissed items will never be shown again. Ignored items will reappear until they are either dismissed or fall off the "front page" of their respective sites.
Content / Subscription Prioritization
On the Python server, Reddit data goes through the additional step of having its new items run through a recommendation / prioritization model, scoring each item for my likelihood of clicking it, and allowing the most interesting items to be brought to my attention first.
The Data
The prioritization model is trained exclusively on my past click / no click data collected using this dashboard. Reddit was the very first content source I added and the one where I have the most data. This is why it's currently the only source that has a prioritization model. That said, once I have sufficient data, the end goal is to have a model for each, or preferably a single generalized model that can handle data from any content source.
The Features
The model features are handcrafted and include a combination of Reddit specific features (e.g. number of upvotes / downvotes, number of comments, when the item was posted, subreddit, etc.) and NLP features on the item's title (tfidf vectors of the cleaned, stemmed title). Note, in addition to the prediction model itself, we also save its associated tfidf transformer so that future predictions use consistent "document" frequencies and vocabularies.
Ultimately, the model data ends up being very "wide" (having many features) relative to the number of training examples. This can lead to overfitting and is something we factor in during the model selection phase.
The Model
The current model used in production is a random forest. Interestingly, based on pure test set evaluation, it is not the best model I've trained. Despite this I use it because:
- My very best model, an ensemble of this random forest and a (necessarily shallow) fully connected neural network, is simply too slow / unwieldy to do predictions in real-time
- The incremental benefits of using this complicated ensemble are very small (~1% increase in AUC vs. just the random forest)
- It's interpretable, which is helpful to make sure it's picking up on real things (e.g. favorite subreddits) as opposed to overfitting to quirks of the relatively small dataset. This is a major advantage over the neural network
- Like other tree-based methods, it does automatic feature selection and can ignore irrelevant features helping combat overfitting from the large ("wide") feature space described above. This is another major advantage over the neural network
- Indeed, despite scoring slightly worse than even the neural network alone, it produces generally more sensible predictions suggesting that the neural network is probably overfitting to some extent
The model is trained using 5 fold cross-validation and final scoring on a held out test set. Hyperparameters (number of trees, number of features to consider at each split, and minimum leaf node size) are selected by a grid search over a small, curated selection of possible values for each.
Ultimately, this training process is very slow. Given this, the model is currently retrained manually and only periodically (when I have the time / inclination).
The Results
The model output is a probability that I will click each item. The results are ranked in descending order by these probabilities and then displayed in the Dashboard. The small, green numbers after each subreddit are the model probability scores (see picture above).
While definitely not perfect, the model does fairly well given the limited amount of data it has to work with. It's able to pick up on things about my interests, for example that I like football, especially college (shown well in the picture above). That said, perhaps it's best advantage over the standard Reddit rankings is that it is more willing to bump up the content from smaller subreddits (e.g. r/cfb over r/nfl or r/machinelearning over r/worldnews).
Enhanced Search
On a separate note, my Personal Dashboard also offers enhanced search capabilities versus the standard Google search available on the default Chrome new tab screen. Specifically, these enhancements are:
Fetching recommended (autocomplete) search queries
Actually, Google already has this, so it's technically not an enhancement. Regardless, it's a must have feature for convenient searching. That in mind, these query suggestions are retrieved by tapping into the same API Google uses for their query suggestions.
Performing a Google search on the query
If I pause on a typed query for long enough, the Dashboard will automatically perform the Google search for the current query in the background and will display the top 3 search results alongside the standard Google query autocomplete suggestions. Clicking or selecting one of these results will take you directly to that page skipping the Google search results page entirely.
Performing a search of my past browsing history on the query
At the same time as the Google search running in the background, the Dashboard, hitting the local Python server, also performs a search of my past browsing history and will display the top 3 search results alongside the standard Google query autocomplete suggestions and the 3 Google search results from above. Once again, clicking or selecting one of these results will take you directly to that page.
As discussed in my Data Acquisition post, I track all my web browsing activity. The way this works is that the lil ai Chrome extension will alert the local Python server each time I visit a new URL. The data is saved and tracked over time. I use this data in a variety of ways, one of which is this browsing history search engine.
The search engine searches over "documents" of web page titles and their URLs. These documents are first cleaned, split into words, and stemmed. The stemmed results are then used to build a search index and a tfidf transformer used to score the candidate documents via the cosine similarity of the query vs. the documents. The cosine similarity is multiplied by the number of times I've visited that URL to yield the final document score used for ranking. The search engine is refreshed hourly so that it incorporates the latest browsing data.
While the ranking algorithm is nowhere near as sophisticated as Google's, it adequately surfaces related documents and more importantly highly prioritizes pages I've visited many times before. That said, perhaps the biggest benefit of this search engine is its ability to surface frequently visited pages that Google cannot index (e.g. private Github repos or Trello boards).
Fetching the top answer from Stack Overflow (where applicable)
Finally, because I use Stack Overflow often, the Dashboard allows me to quickly fetch the top answer for any Stack Overflow question. To do this, all I have to do is highlight the Stack Overflow link in the suggestions box and press tab. The Dashboard will then scrape the page, determine the top answer, and display it nicely to the side. (See the demo video for an excellent example of this.)
Design
It was important to me that my Personal Dashboard be very minimalist and not cluttered. I took a lot of inspiration from the Google front page in this regard. As such, I opted for a plain background as opposed a picture based one as seen on many other Chrome new tab page replacements (it also loads faster that way). Also in keeping with this goal, new content is NOT automatically displayed nor are there any indicators for how many new content items there are. Browsing the list of new items is meant to be entirely optional and to be done in batches only when convenient.
The background is dark so that it's easier on the eyes. Meanwhile, the rounded corners on the search box and buttons help give the page an inviting and modern feel.
Weather
I check the weather often, and my favorite weather report is actually the Google (desktop) search results one. Given this, clicking the cloud icon in the bottom right of the Dashboard is a shortcut to this weather page. (See the video below for a demonstration of this.)
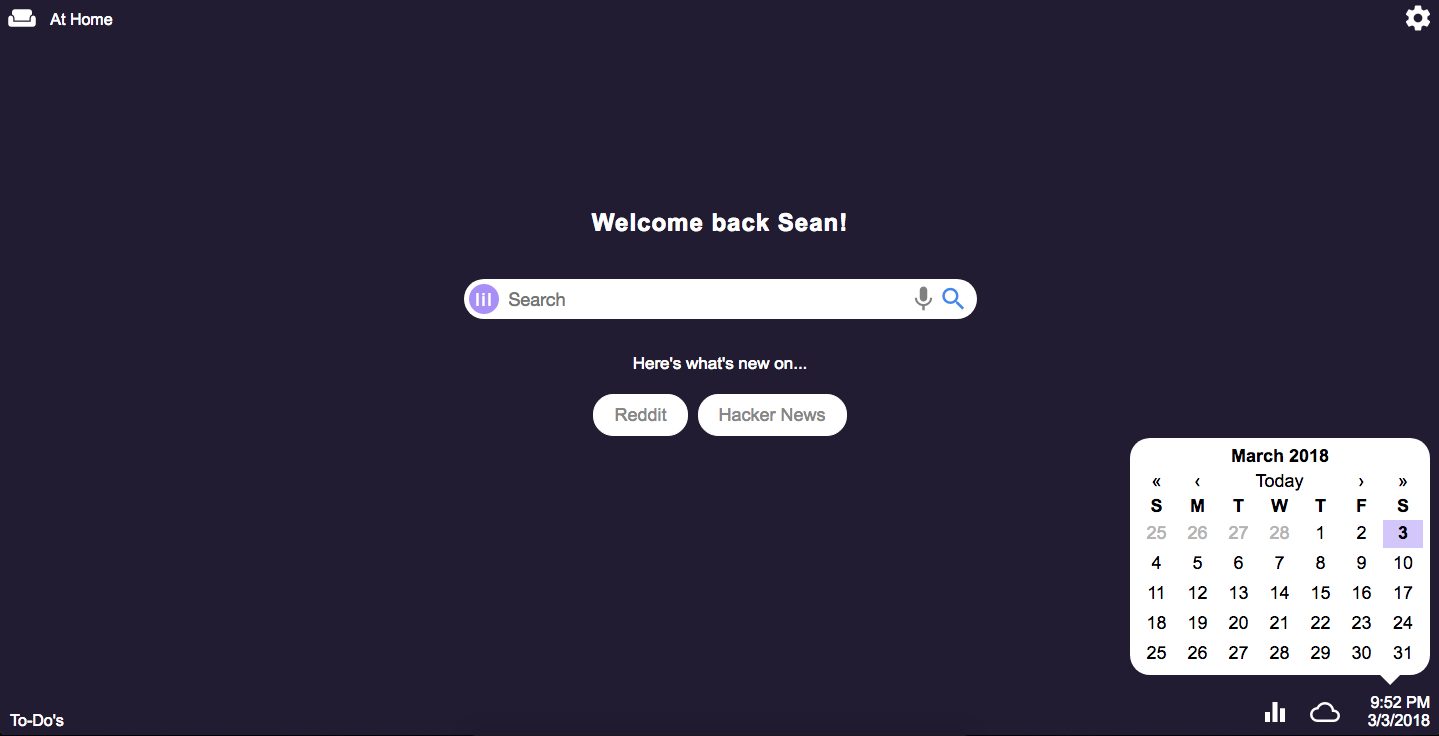
Calendar
One thing sorely missing on Mac is a simple monthly calendar. This annoyed me for a long time, so I added one to the Dashboard.
Web Viewing Statistics
As mentioned above, I track all my web browsing activity, and this Personal Dashboard serves as an excellent way to inspect this data regularly.
Clicking the bar chart icon at the bottom right of the Dashboard brings up a sorted bar chart displaying the sites I visit most often (not shown here for privacy reasons). I use this data to track how my web browsing habits are changing over time and to suggest new sites / features to add to the Dashboard. Indeed, I started with just Reddit. YouTube, ESPN, and Hacker News were all added due to this data driven approach, as was the Stack Overflow smart search feature.
Demo
To conclude, since my Dashboard isn't publically available, please enjoy this short video demoing several of the features discussed above.