WARNING: This article will show flaws of the much beloved Google search results, which once you see, may be hard to unsee and lead to future annoyance. You have been warned.
The Problem
Issue #1
First off let me say, Google is amazing and super useful. With just a few keystrokes, it gives you access to all the world's online knowledge. But... Google is not perfect and in certain situations could even been considered "dumb". Take the following scenario for example:
- You're in New York City (like I am now)
- You're on your computer (say at work)
- Your friend, who you're supposed to meet up with, texts you and says to meet them at some address you've never been to before
- For the sake of this example, let's say that address is 123 Broadway
- Naturally, having never been to this address before, you google it
- You (or at least I) get this as a result:
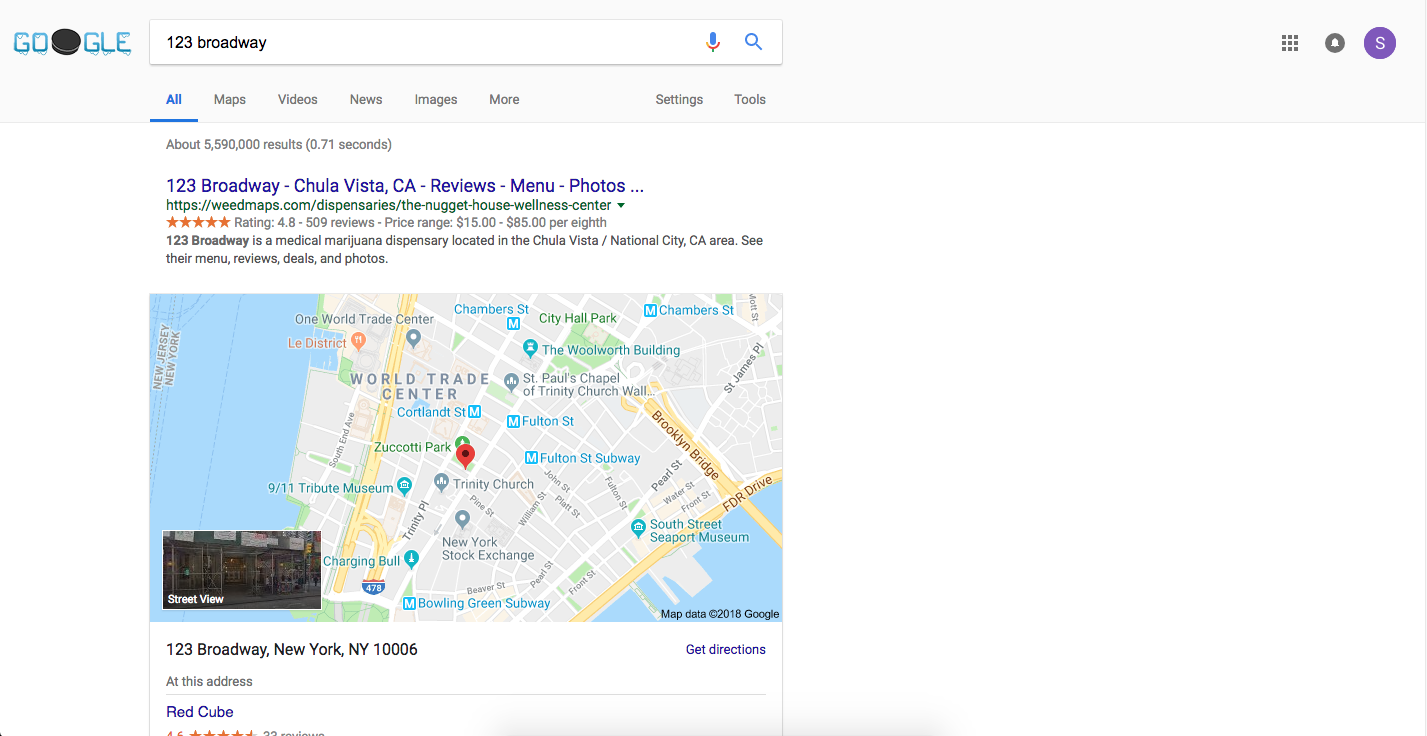
(Try clicking the image to see what you get)
Ah yes! The 123 Broadway marijuana dispensary in Chula Vista, CA. Exactly what I wanted! Now my boss thinks I'm searching for weed during work hours. Thanks Google! /s
In all fairness though, Google does rank the result we actually want at #2. Not to mention, the result we want is almost always on the first page.
So then, the issue it seems is not the results Google surfaces, but how it ranks the top results. To describe it another way, Google does a great job of picking out the most relevant links from all the links on the entire web, but not as great a job in determining which of those top candidate links is best (global vs. local search ranking).
Issue #2
But, even if Google does get it right and ranks the result we actually want #1, the result is not always as useful as it could be. To see what I mean, let's continue with our address example, but instead search for 1234 Broadway:
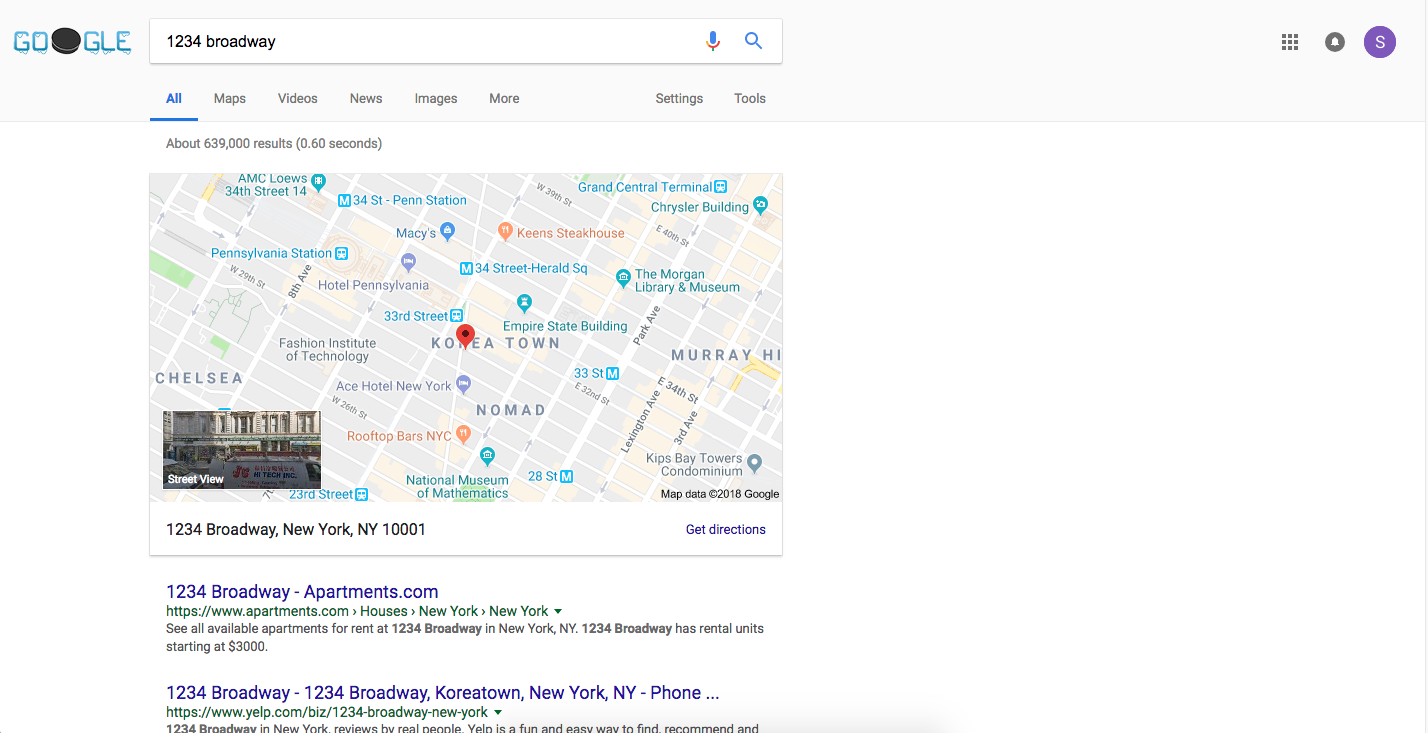
(Try clicking the image to see what you get)
Perfect, we get the common sense result at #1! But, is this really what we want? You know what would be more useful, if instead of taking us to the standard Google search results page with a static map image, it took us here instead:
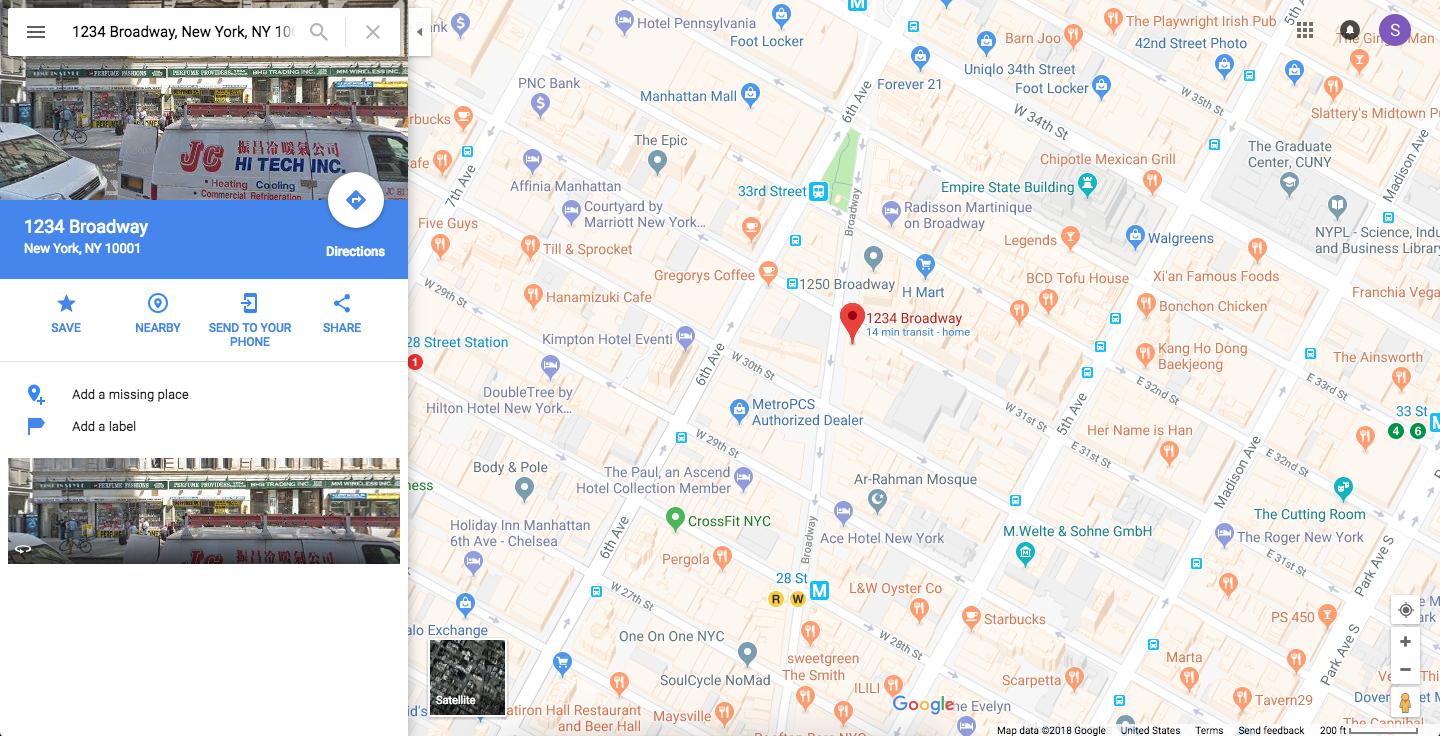
Now the map is big enough that we can read everything easily; we can zoom in or out; we can pan to our current location, easily get directions, or jump into street view. Basically, we get what we actually want without any superfluous steps.
To Summarize
Google search is great but could be better at knowing what we actually want with a given search query and then getting us there quickly and efficiently.
While we've demonstrated this already with addresses, it applies for many different types of searches as well:
- Pictures of dogs does not take you to Google Images
- GOOG does not take you to Google Finance
- Facebook or YouTube does not take you directly to these sites even though these are the consistently among the most popular search queries with millions of searches a month
- Even if you listen to Spotify everyday, searching for it will rank the generic spotify.com #1 as opposed a more potentially more useful login or listening page
- Have a programming question? Google is not going to take you to Stack Overflow even if it knows the best / most popular answer is there
- Etc.
In short, even Google has its flaws. Search can still be better.
My Solution
My solution to the problem is the lil ai Search Assistant, a Chrome extension that provides real-time Google search result personalization, bumping up the links I'm most likely to click. And, for my most common searches, it will navigate directly to the desired page.
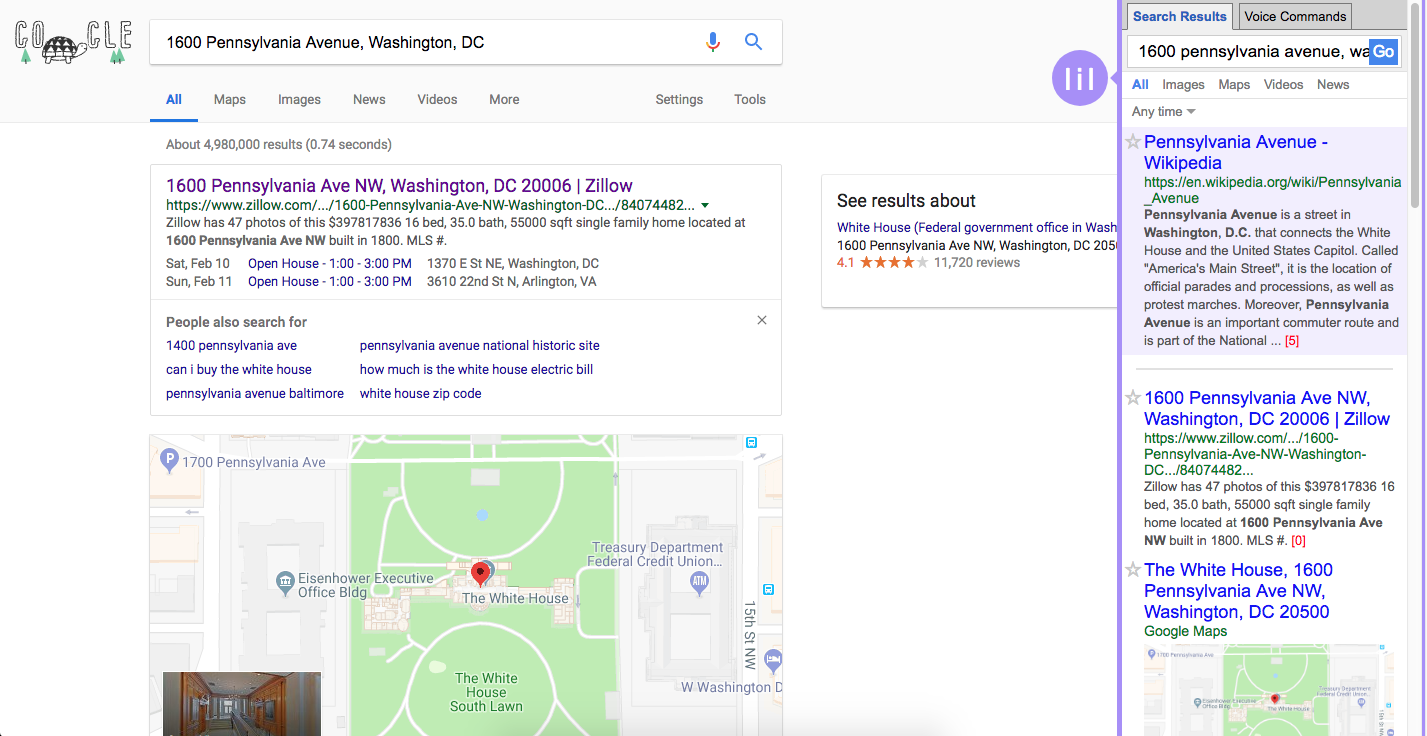
That's a lot to absorb at once, so let's take that piece by piece:
Chrome Extension
First, the solution obviously requires some kind of web front-end because I'm not going to switch programs every time I want to do a search. This means I can't avoid using at least some HTML / CSS / Javascript.
Secondly, I use Google Chrome as a my browser, so naturally any solution will have to work there.
Most critically, I need to get search results from Google somehow because I'm not going to build crawl the entire web to build a search engine. Given Google doesn't offer an API and that Google search results are notoriously difficult to scrape (the page is almost entirely rendered by Javascript), I either have to do a scrape using something like Selenium or in Javascript natively.
Given these requirements, Chrome extensions—essentially little bits of code (Javascript + HTML / CSS) that run as part of your browser—offer a number of appealing benefits:
- Always running: If Chrome is open and the extension is enabled, it's always running (like a server). This offers a the ability to persist data across pages which is super helpful for an application like this
- Can run on pages that are not your own: With a Chrome Extension you can insert code into any webpage. This makes them amazing for scraping even the most complex websites, and for displaying information wherever it is most useful / convenient
- No server required: Unlike a regular website which requires a server to host it, all the files live on your machine in an extensions directory with all the other Chrome related files
- Super scalable: A Chrome extension is basically just a zipped directory. They're small, lightweight, and easy to share
- Data security: Since there is no server to call out to / receive data from, there is no risk of data being intercepted in transmission
Ultimately, what this looks like in the final product is the search results pane you see at the right of the picture above. This pane is inserted each time you do a Google search and displays your recommended search results (much more on this below).
Real-Time
For any sort of search result personalization / augmentation, the results need to be real-time to be of any use at all. This means keeping latency down is key.
For the Search Assistant, all the action happens as soon as I press enter on a search query. The search results are obtained, parsed into data, fed into a machine learning model to predict which results I'll be most interested in, and finally the output displayed back to me.
On my computer, this process takes ~2-3 seconds total though of course results would vary for others depending on internet and processor speeds.
Currently, the machine learning model also retrains itself in real-time. However, with increased data the retraining has gotten slower and slower and at some point will need to be moved to either scheduled, job based training or training on a server.
Results Personalization
The Search Assistant uses in-browser machine learning to predict which search results I will like most.
The Data
The training data is derived entirely from my own past search results. The target labels are derived not from clicks (which can be skewed by poor suggestions / rankings from Google), but from my own starring of results (max one per search query). The stars (located just to left of each search result title) indicate that this result is one I want. Queries where I don't star anything are excluded from the dataset.
My dataset is currently a little over 2,000 rows (search results), but I started from 0 adding ~10 for each query where I starred a result. Because data is so limited, I currently use all the data for training. The real world is my test set, and I'm the guinea pig.
The Features
For training the model I use a fairly large set of handcrafted features looking at things like what Google ranked the link, the website of the link, past visits to the website, type of search result (e.g. standard link, video, map, etc.), how the query relates to the links title, etc. To keep processing time low, I currently do no NLP on the title or description text (word counts, tf-idf, embeddings, etc.), but that definitely could be worth exploring in the future.
The Model
The model itself is a simple decision tree selected because:
- It needed to be simple / fast because it needs to train and run in real time in the browser
- It needed to be serviceable even with very little data
- It's interpretable, which is helpful to make sure it's picking up on real things (e.g. preferred websites) as opposed to overfitting to quirks of the relatively small dataset
- It deals well with categorical data and per my implementation does not require categorical fields to be one-hot encoded thereby reducing the data footprint
- It also does automatic feature selection and can ignore irrelevant features completely
The Results
The model output is a probability that I will star each result. The search results are ranked in descending order by these probabilities and then displayed in the Search Assistant's result pane with the top, highlighted result being its recommendation. The red bracketed numbers at the end of each links description text are what Google ranked that link (0 = #1, 1 = #2, etc.).
As might be expected, the model is quite conservative initially, often giving the same results as Google. However, as it gets a little more data, it starts picking up on things like favorite / preferred websites. For example, in picture above, the model actually ranks the Pennsylvania Avenue Wikipedia page #1 because I often star Wikipedia pages (Google had it 6th). However, in this case, the model is actually wrong because in reality I would star the map (granted I would prefer the Wikipedia page over Google's recommended Zillow page (?)). Similarly, when I do a search for a programming question, I've noticed that the model will bump up Stack Overflow answers because I often prefer them over documentation pages for many questions.
Ultimately, while the model is far from perfect, it does do fairly well for its limitations as a basic decision tree that has to run in real-time, in the browser with small data.
Direct Navigation
In addition to being used as the personalization model's target variable, the stars mentioned above also tell the Search Assistant to navigate directly to that page if it ever sees the search query again. To use a real example, if I search for "espn" I will be taken straight to ESPN.com instead of the Google search results page because I starred this result in the past.
I've also experimented with having the Search Assistant always navigate to the page it thinks I will like most. It really feels like magic when it works well, however when it doesn't it can feel jarring. Given this, I currently have the feature disabled but am considering turning it on again in future for results where the model has high confidence.
Demo
To conclude, since the lil ai Search Assistant isn't publically available, please enjoy this short demo video (showing how it's clearly learned that I like maps!).